A well-reasoned error strategy is vital to the health of backend services. It’s important to consider how to handle an error, and if it cannot be handled then how to log it, what information is useful to be logged with, and who gets notified.
The backend service responsible for launching one-to-one projects on 99designs was failing for some number of customers. Unfortunately because of a mixture of problems with the existing error strategy, it was hard to get a clear understanding of the scope of errors occurring. Errors were being handled multiple times, there were many redundant or unimportant errors, and logged errors had inconsistent metadata. This lack of intentional strategy led to drifting standards across codebases.
We spent some time investigating our existing error strategy and inventing a model for how our errors within our Go Twirp services should operate. This post gives some context on Go errors and Twirp, details on some of the issues we faced, and lays out our strategy for error handling going forward.

It’s worth mentioning that although we use Twirp for inter-service communication, this advice should equally apply to gRPC setups, or other RPC frameworks that use Go errors as part of their handler signatures.
Background
—
At 99designs, our blueprint for new services consist of small Go binaries, that communicate via Twirp, either between each other, or to our frontend through our GraphQL aggregation service.
Errors in Go
Errors in Go are just values. Apart from having the built-in error interface, they are more a language convention than feature. By convention an error can be returned from a function if an error case occurred, and it is the responsibility of the caller to check this value and take appropriate action.
Any type can be an error as long as it implements the error interface. The default error type returned by the errors package is just a string containing the error message.
This model, in contrast to a feature like Exceptions, forces a developer to think about and handle error cases in the immediate context of the calling code. Having this be a strong convention also allows tools to easily lint for error checking and ensure good practises are maintained.
However one common anti-pattern we see in our services, is when a function returns an error, it is simply returned back up the stack to the caller, which can often similarly return the error to its own caller. In some ways this is the reverse problem that Exceptions have; the developer returns an error and hopefully there is something up the stack that knows the correct thing to do and will deal with the error appropriately.
Panic and Recover
The other error mechanism Go has are panic and recover statements. This mechanism is similar to an Exception, in that execution of the current function will stop and return to the caller. Deferred functions are executed however as the panic propagates up the stack. You can read more about how panic and recover work in this blog post.
Error Wrapping
Since Go errors are just values, Go does not provide much in the way of tooling in the standard library to work with them. However Go 1.13 added some utilities for dealing with common error patterns; specifically providing a standard way of wrapping errors with additional context made popular by packages like github.com/pkg/errors.
Twirp and Errors
Twirp is a protobuf API protocol over HTTP. Writing a Twirp server is convenient, because a developer can focus on service logic rather than transport or routing concerns; all that is required is writing the protobuf definition and implementing generated RPC handlers. These handlers have an error in their return type, and the Twirp server attempts to convert returned errors from a handler into an HTTP equivalent error that is returned to the client.
Twirp defines a range of useful error types that are mapped onto HTTP equivalents. Handlers may also return any valid Go error type, which Twirp will treat as if it was a twirp.Internal error mapping it onto an HTTP 500 response. We’ll unpack what this means for our handler code in the discussion below.
Bugsnag
Bugsnag is the error reporting and monitoring service we use. Errors can be submitted to Bugsnag using the Notify method of their Go client package. Because Go errors are just values, the error interface does not provide methods for retrieving stack information.
So the Bugsnag client will wrap an incoming error with stack information using the Go runtime package, and submit that along with any additional meta-data to Bugsnag. This can be done anywhere using the github.com/bugsnag/bugsnag-go/errors package, and is also done automatically upon call to Notify.
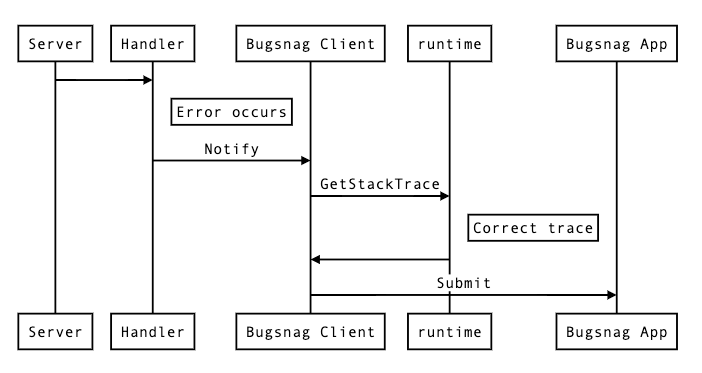
Bugsnag will collate these errors and attempt to group them such that you can see the same error grouped together. Operations such as “ignore” or “mark fixed” can then be performed on these groups.
Constructing a stack trace like this works well for normal calls to Notify, but falls short when attempting to put in place automated notifications in a part of code that is outside the stack from where the error occurred. This is because the default grouping in Bugsnag groups errors by 2 metrics: the “type” of the error (which is Go is usually just a string), and the file location of the top frame of the stack trace sent by the client. So when attempting to write something like a global error handler, stack information can be lost, and all errors can appear to originate from the place that Notify is called in such a handler.
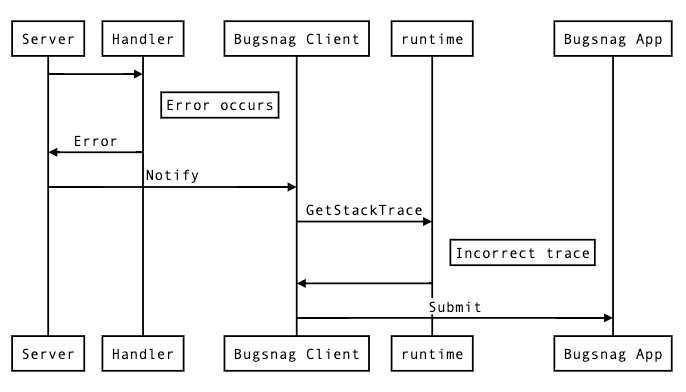
Problems with Existing Error Strategy
—
With that context in mind, let’s take a look at some of the common issues we ran into in our Go Twirp services with our existing error strategy.
Twirp Handlers Returning Errors
As mentioned earlier, generated Twirp interfaces expect back a response message, and an error from the handler function. Any error that is not typed with a Twirp error code is wrapped in a Twirp internal error and treated as a server error.
This can be a problem in cases where there is an error with the request itself. An example might be attempting to retrieve a non-existent record, attempting an action that is not permitted, or a malformed request body. These are errors that are caused by the client side, so treating them like an internal server error does not indicate to the client that the problem is their responsibility.
Returned errors are also transmitted back to the client, and can lead to accidental leaking of information that the client should not otherwise be able to access.
Bespoke Calls to Bugsnag Notify
In the absence of some sort of higher-level automatic error handling code, developers are forced to put bespoke calls to notify Bugsnag at points they think they will likely encounter an error.
There are a number of issues with this approach. Firstly it’s inconsistent, and you can’t get a good picture of all the errors occurring on your platform. Errors are only logged in places that a developer remembers to call Notify.
Secondly, unless you terminate a handler on the spot, you run the risk of sending a notification for an error multiple times. This can create confusion when reviewing errors, as multiple notifications have the same source.
Bad Stack Traces
The generated Twirp server does provide hooks for running code when an error is returned from a handler. This initially seems like the perfect place to do an automated Notify call, however recall that Go errors do not have any Stack information associated with them. Recall also that Bugsnag groups errors by the last stack frame.
The automatic Notify call will have the same stack trace for all errors, and therefore all errors will be grouped together in the Bugsnag interface, meaning that bulk actions cannot be performed on subsets of errors.
No Context on Returned Errors
When returning an error from a function, it is often important that context is added to the error so that either the caller, or a developer reading the error has a better understanding of the error condition that has occurred.
Many existing calls do not do this however and return the raw error back to the caller. This leaks implementation details, and can be difficult to trace what the actual error condition is.
A Better Error Strategy
—
Our Go microservices are small enough that it should be possible to reach “Inbox Zero” in Bugsnag; all errors should either be ignored because they are unimportant, or require the attention of a developer and should be put on a backlog, fixed, and afterwards marked as resolved. Getting to this point is extremely useful, as it means that any reported error from a service can be investigated by an engineer in a timely fashion.
In practise reaching this might be difficult, but we’ve adopted some of the following strategies in an attempt to get to this ideal scenario.
General Go Error Handling
When an error condition occurs in general Go code, simply returning an error might not always be the best course of action. Consider wrapping the error with additional context if it will make it clearer to the caller what has occurred using the Go 1.13 %w placeholder with fmt.Errorf.
func doOperation() error {
err := callService()
if err != nil {
return fmt.Errorf("operation failed: %w", err)
}
}
Panic should be used sparingly in invariant cases where a situation should never be possible. A panic indicates that a function does not think returning an error value would be useful for the caller. In these cases a developer is likely required to make a fix.
Explicit calls to Notify can still be used, but should only be used in situations where a developer wants to know that a situation occurred that was still able to be recovered.
Wrapping Errors
Errors should be wrapped before returning if the function can add useful context with a more specific error message, or wants to decorate an error with additional metadata. Useful context might include information about related domain entities, or related structured data that a caller could use to assist handling the error.
Automatic Bugsnag Notification
So to address issues with bespoke Notify calls, we need an automatic way of notifying Bugsnag when an error occurs that we think requires a developer’s attention. And we need to do this in such a way that it preserves a useful stack trace, and grouped correctly in Bugsnag.
Our solution is to instate a panic handler high in the stack off the application that can recover, and automatically call Bugsnag with the error. The benefit of using a panic, is that the stack is preserved for all defer calls, and so an accurate stack trace can be constructed from the point of the panic.
func BugsnagMiddleware(w http.ResponseWriter, r *http.Request) {
defer func() {
if p := recover(); p != nil {
err := NewErrorWithStackTrace(p)
bugsnag.Notify(r.Context(), err)
}
}()
next.ServeHTTP(w, r)
}
In this example NewErrorWithStackTrace calls the go runtime to get the current stack, and removes enough frames from the top until the top frame of the stack is the location of the original panic. A stripped down version of this function might look like:
func NewErrorWithStackTrace(p interface{}) *Error {
frames := GetStackFrames()
lastPanic := 0
for i, frame := range frames {
if frame.Func().Name() == "runtime.gopanic" {
lastPanic = i
}
}
ret.frames = ret.frames[lastPanic+1:]
return &Error{err, frames}
}
We add this stack information to a custom error type that meets the ErrorWithStackFrames interface exposed by the Bugsnag client.
Twirp Handlers
Errors that bubble up to a Twirp handler generally fall into one of two categories, client errors, where the error lies with the request and should be handled by the caller. And server errors, where the downstream service is at fault.
1. Client Errors
Equivalent to an HTTP 400 range status code. These are errors that are the responsibility of the client. Authentication and authorisation errors fall into this category, as do validation errors. Other examples include malformed requests, invalid arguments, or resources that could not be located.
These should be returned from the handler using the appropriate twirp error codes. Example:
err := json.Unmarshal([]byte(req.JSONBlob), &dst)
if err != nil {
return nil, twirp.NewError(twirp.Malformed, fmt.Sprintf("could not unmarshal request: %v", err))
}
2. Validation Errors
Some concerns, such as validation, require metadata to be returned with errors. There are two main ways to implement this case.
The first is to simply include it as part of the response message. The response message itself might indicate whether the request was a success, and if not what errors were found. This is useful for validation scenarios where the client may want to display errors encountered to an end user, and each error might have some additional metadata associated.
The other implementation is to use the Twirp error metadata map—a simple key/value map that is a feature of Twirp errors, and is available to read on the client.
We don’t have a strong recommendation here, some judgement is probably necessary. We are keen to hear how developers have found the experience of working with each case.
3. Server Errors
A server error is any error that occurs not because of the incoming request, but for any other reason that the client could not predict. These errors are considered unrecoverable, and therefore should be a panic inside the handler itself. Example:
err := db.Insert(record)
if err != nil {
panic(fmt.Errorf("could not perform database insert: %w", err))
}
These errors will be caught by a top-level panic handler and a stack trace generated at this point as described above.
There may still be some cases where a server error occurs but is expected for some reason. These cases do not warrant a developer looking at them. In such cases any error can be returned and the client will get a 500, however no Bugsnag notification will be sent.
It’s worth noting that the standard library http.Handler interface does not provide an error return value in the signature of ServeHTTP. This is a better design as it forces the handler to call panic in the case of an unhandled error occurring. By having a separate channel for errors, Twirp (and by extension grpc) creates an opportunity for users to simply return errors they incur, instead of taking a considered approach on a per-error basis.
Conclusion
—
While this is a topic that can seem boring at first glance, upon unpacking is actually complex and rewards careful consideration. Being intentional about the handling of errors can make it easier for teams to understand problems that a service is having, and quickly prioritise and resolve issues as they arise.
A good error strategy has clear guidelines defining patterns developers can reach for to handle common use-cases. While these patterns might not fit all scenarios, they are instructive and help to better inform developers about what good error handling looks like.
In this particular case, after adopting this strategy we were able to clearly identify the scope of affected customs, and the issues they were running into. This enabled us to prioritise fixes for common problems, and allowed us to trust the error reporting on an ongoing basis.
Going forward we intend to adopt this pattern across all our services, and hopefully get to a place where our backends are informing us when things go wrong in a way that we can quickly respond to.
The post Go Service Error Strategies appeared first on 99designs.
No comments:
Post a Comment